AgentOps isn’t about shipping an agent faster. It’s about ensuring the agent remains:
- correct
- safe
- reliable
- auditable
…as it evolves.
My AgentOps Evaluation Stack
Once I accepted that evaluating conversations wasn’t enough, I needed a way to evaluate agent intelligence — deterministically, repeatedly, and before anything reached production. That meant working bottom‑up.
To move from agent demos to AgentOps, I needed an architecture that made responsibilities explicit:
- what decides
- what evaluates
- what orchestrates
- what enforces correctness
Here’s the structure I ended up with:

1. agents/ — Where Decisions Live
The agents/expense_agent.py file represents the decision-making core.
This agent does one thing only:
- take user input
- extract structured details
- apply policy
- return a structured decision
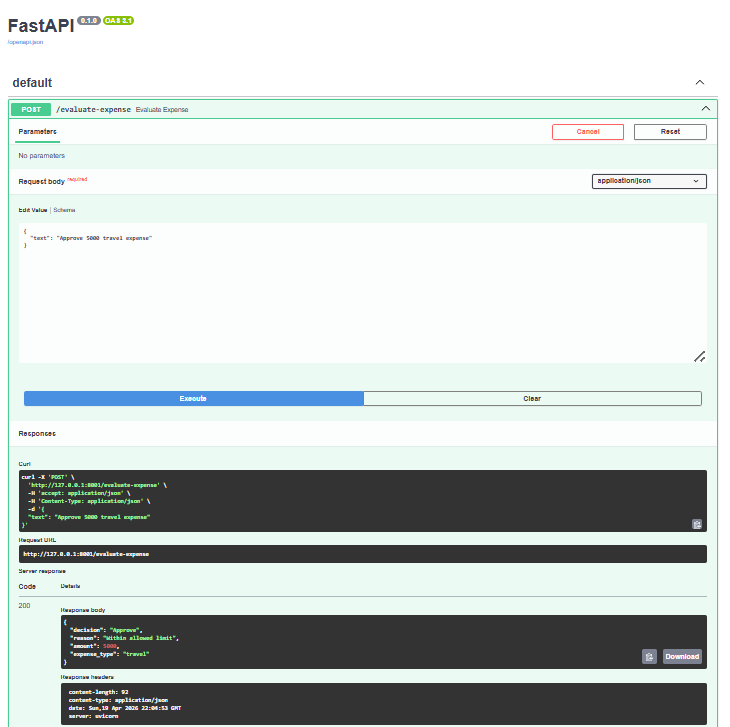
{
"decision": "Approve | Reject",
"reason": "…",
"amount": 5000,
"expense_type": "travel"
}You cannot evaluate intelligence if the agent output itself isn’t deterministic and structured. By isolating the agent here:
- it can be reused by Copilot, Foundry agents, or backend services
- it can be evaluated independently
- it can’t “hide” behind conversational phrasing
2. tools/ — Policies and Formatting, Explicitly Separated
The tools/ folder holds logic that supports the agent but should never be mixed with orchestration.
policy_checker.py
This file contains pure policy logic: amount thresholds, luxury constraints and deterministic rules, This allowed me to answer a key evaluation question later - Did the agent fail because the policy was wrong or because reasoning was wrong? Without this separation, failures are impossible to diagnose.
formatter.py
Formatting was isolated deliberately. By treating formatting as a tool:
- prevented evaluation noise from phrasing changes
- ensured LLM judges saw consistent input
- avoided “false regressions”
3. evals/ — The Heart of AgentOps
This folder is where the AgentOps mindset lives.
test_cases.json
It’s a dataset which contains:
- standard cases
- edge cases
- ambiguous phrasing
- adversarial input
- noisy real‑world language
This dataset evolved over time and whenever I added new scenarios, regressions surfaced immediately.
native_evaluator.py
This file introduces LLM‑as‑a‑Judge, powered by Azure AI Foundry models. Important design choice:
- the judge evaluates reasoning quality
- it returns structured JSON
- it never overrides deterministic correctness
run_evals.py
This file ties everything together. For each test case, it:
- Runs the agent
- Applies deterministic correctness checks
- Invokes the Foundry‑backed LLM judge
- Classifies failure types
- Aggregates accuracy
- Generates an HTML report
- Exits with a CI‑friendly status code
This is where I stopped trusting outputs and started trusting signals.

4. client/ — Azure AI Foundry as an Evaluation Dependency
The foundry_client.py file abstracts model access. Using Foundry models for evaluation means:
- consistent judge behavior across environments
- alignment with enterprise model governance
- parity between development, CI, and production
5. .github/workflows/ — When Evaluation Became Enforcement
The agent-evals.yml workflow is where this stopped being an experiment. Every change:
- runs run_evals.py
- uploads the HTML report
- fails the build if accuracy drops
This was the moment I crossed into AgentOps. If evaluations can’t block a deployment, they’re suggestions — not safeguards.
6. api.py — Making the Agent Reusable
Only after correctness and evaluation were locked down did I expose the agent via a thin FastAPI wrapper. This turned the agent into a capability, not an app. Now it could be:
- called by Microsoft Copilot Studio
- reused by Foundry agents
- evaluated without changing orchestration
- trusted across multiple systems
Final Thoughts
Most teams are building agents. Very few are building AgentOps. If your evaluation strategy only asks “Did the agent respond?” You’re missing the more important question: “Can I trust this system as it evolves?”
That’s where real AgentOps begins.



